Le 30 mai 2026, le projet Needle publié par Cactus Compute a recueilli 667 points sur Hacker News en moins de 24 heures, propulsant un débat technique au rang de signal stratégique pour les PME. Pour la première fois, un modèle IA léger embarqué de 26 millions de paramètres atteint des performances de tool calling comparables à des modèles dix fois plus gros, et tient dans 14 mégaoctets une fois quantifié. Concrètement, vos applications mobiles, montres connectées et objets du quotidien peuvent désormais embarquer un agent IA sans serveur, sans coût marginal et sans envoyer la moindre donnée dans le cloud. Voici ce que cette bascule change pour votre PME.
Qu'est-ce que Needle, le modèle IA de 26 millions de paramètres open-sourcé par Cactus Compute ?
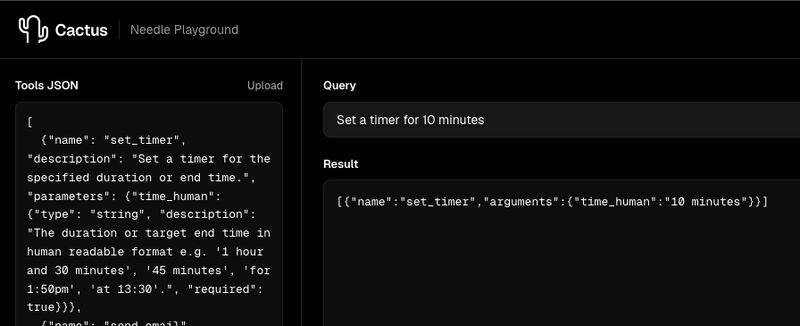
Needle est un modèle de tool calling distillé depuis Gemini 3.1 par Cactus Compute et publié en open source en mai 2026. Il pèse 26 millions de paramètres, soit environ 200 fois moins que GPT-4 ou Claude Opus, et tient dans 14 mégaoctets une fois quantifié en INT4. Sa fonction n'est pas de tenir une conversation : il est entraîné spécifiquement à comprendre une demande utilisateur, à choisir le bon outil dans un catalogue, et à émettre l'appel JSON correspondant.
L'équipe a démontré sur Hacker News que Needle surclasse FunctionGemma-270M, Qwen-0.6B, Granite-350M et LFM 2.5-350M sur le tool calling single-shot, alors que tous ces modèles concurrents sont nettement plus volumineux. Vitesse de prefill : 6 000 tokens par seconde. Vitesse de décodage : 1 200 tokens par seconde. Sur un smartphone, les agents répondent en quelques millisecondes. C'est la première fois qu'un modèle aussi petit atteint ce niveau de fiabilité fonctionnelle.
Pourquoi cette annonce change la donne pour vos outils PME en 2026
Jusqu'ici, intégrer un agent IA dans un produit imposait un coût d'API par requête et une dépendance permanente au cloud. Avec un modèle léger embarqué comme Needle, le calcul se déplace vers l'appareil de l'utilisateur. Pour une PME qui édite une application métier, une boutique en ligne ou un outil interne, trois conséquences immédiates apparaissent.
Premièrement, le coût marginal d'une requête IA tombe à zéro. Vous ne payez plus OpenAI, Anthropic ou Google à chaque interaction. Deuxièmement, la latence disparaît : pas d'aller-retour réseau, l'agent répond hors-ligne. Troisièmement, la donnée reste sur l'appareil, ce qui simplifie radicalement votre conformité RGPD et désamorce une part des objections clients sur la protection des données.
J'ai déjà observé chez deux clients Treelink l'impact concret de cette logique on-device. Le premier, un cabinet d'expertise comptable, expérimente un assistant local qui ne sort jamais des postes utilisateurs pour annoter les factures fournisseurs. Le second, une marketplace artisanale sous Webflow, étudie un widget de recherche conversationnelle qui tournerait dans le navigateur sans appel serveur. Dans les deux cas, la bascule on-device répond à une exigence client précise plutôt qu'à un caprice technique.
Comment fonctionne Needle techniquement : SAN, distillation, 14 Mo
L'architecture de Needle s'appuie sur un Simple Attention Network (SAN), une variante de transformer dans laquelle les couches feed-forward classiques ont été retirées. Il reste 12 couches d'encodeur et 8 couches de décodeur, avec attention masquée et cross-attention. Cette simplification radicale explique le faible nombre de paramètres tout en conservant la capacité d'extraction de motifs nécessaire au tool calling.
Le préentraînement a tourné 27 heures sur 16 puces TPU v6e avec 200 milliards de tokens, suivi de seulement 45 minutes de post-entraînement sur 2 milliards de tokens synthétiques d'appels de fonctions. Les données synthétiques couvrent 15 catégories d'outils : minuteurs, messagerie, navigation, domotique, etc. Le coût total du training, selon Cactus Compute, reste inférieur à celui d'un mois d'API GPT-4 pour une PME active.
L'idée centrale de l'équipe est que le tool calling n'est pas du raisonnement, c'est de la récupération et de l'assemblage. Le modèle doit faire correspondre une requête à un nom d'outil, extraire les valeurs des arguments et produire un JSON. Cette tâche bien définie supporte une compression massive sans perte de qualité, à l'inverse de la conversation libre.
Trois cas d'usage concrets pour une PME en 2026
Pour une PME, un modèle IA léger embarqué débloque trois familles d'applications immédiates. La première, c'est le widget conversationnel sur votre site web. Imaginez un module de prise de rendez-vous où le visiteur dit « je voudrais un créneau jeudi matin » et où Needle parse l'intention, sélectionne l'outil calendrier et propose les disponibilités, sans appel API externe.
La deuxième famille, c'est l'application mobile métier. Pour un artisan, un commercial terrain ou un coursier, un agent local qui comprend les commandes vocales et déclenche les bonnes actions dans l'app fonctionne même sans réseau. La troisième famille, c'est l'objet connecté. Une borne d'accueil, une caisse, un capteur IoT peuvent désormais intégrer un agent IA fiable pour 14 Mo de mémoire flash.
Sur la stratégie d'agents IA en SEO, j'avais déjà documenté l'utilité de petits modèles spécialisés pour automatiser des tâches répétitives sans facture cloud. Needle pousse cette logique d'un cran : la spécialisation ne se fait plus côté prompt mais côté poids du modèle. La logique métier que vous codifiez aujourd'hui dans un prompt long de 4 000 tokens devient demain un fine-tuning de 45 minutes sur votre catalogue d'outils.
Côté business model, cette mutation favorise les PME éditrices de logiciels métier. Sur un site Webflow propre comme ceux que je livre via l'expertise Webflow Treelink, intégrer un widget IA léger demain reposera sur quelques lignes de JavaScript, là où il fallait hier un backend dédié et un budget API. Sur dix dossiers que j'ai accompagnés en 2025 chez Treelink, six concernaient l'intégration d'IA dans une application existante, et la facture API mensuelle freinait systématiquement le déploiement à grande échelle. Avec un modèle on-device, le coût de production redevient prévisible, ce qui permet d'élargir la couverture fonctionnelle sans renégocier le pricing client. C'est un argument commercial fort pour les éditeurs qui vendent à des PME elles-mêmes sensibles aux coûts variables.
Quelles limites avant de déployer un modèle IA léger embarqué ?
Needle excelle sur le tool calling, pas sur la conversation libre. Si votre projet exige de générer du texte long, de rédiger des emails, de raisonner sur plusieurs étapes ou de synthétiser des documents, vous avez toujours besoin d'un modèle frontier comme Claude Opus, GPT-5 ou Gemini 3.5 Flash. Needle est un composant complémentaire, pas un substitut. La stratégie d'agents IA proactifs repose toujours sur une orchestration multi-modèles.
Autre limite : le déploiement on-device suppose une équipe technique capable d'intégrer un binaire de 14 Mo dans une application mobile ou web, de gérer le cycle de vie des poids et de surveiller la qualité. Pour une PME sans équipe produit dédiée, le passage par un éditeur SaaS qui embarque Needle dans son offre reste plus rapide. Plusieurs éditeurs français devraient l'intégrer dans les six prochains mois selon les commentaires du fil Hacker News.
Enfin, la fiabilité d'un modèle 26M reste dépendante de la qualité de votre schéma d'outils. Plus vos descriptions de fonctions sont claires, plus Needle performe. C'est un investissement amont qui rappelle ce que je vois sur les déploiements OpenAI Agents SDK chez les clients Treelink : la qualité des prompts et des schémas pèse plus lourd que la taille du modèle.
Comment vous positionner dès aujourd'hui face à cette bascule on-device
Trois actions concrètes pour anticiper. Premièrement, cartographiez vos cas d'usage IA actuels et identifiez ceux qui sont strictement du tool calling : prise de commande, recherche de produit, déclenchement de workflow. Ce sont des candidats au déplacement on-device dès 2026. Deuxièmement, dialoguez avec vos éditeurs SaaS pour savoir s'ils prévoient d'intégrer Needle ou un équivalent. Troisièmement, sur votre site Webflow ou WordPress, expérimentez un widget léger avant que vos concurrents ne le fassent.
Pour la visibilité GEO, l'enjeu est différent mais réel. Les agents IA qui interrogent votre site pour répondre à un utilisateur final s'appuient encore sur des modèles cloud, mais Needle préfigure une vague où les assistants personnels embarqués trieront eux-mêmes les sources. Préparer dès maintenant des contenus structurés, citables et avec un schéma propre reste la meilleure assurance, comme je l'explique en détail dans mes articles sur le blog Treelink.
L'open source Cactus Compute publié sous licence permissive permet à n'importe quel développeur de tester gratuitement le modèle. Les poids sont sur Hugging Face, le pipeline de génération de données synthétiques est sur GitHub, et un playground local permet de fine-tuner Needle sur votre propre catalogue d'outils via une interface web.
Ce qu'il faut retenir de Needle pour votre PME
Needle marque une rupture : un modèle IA léger embarqué de 26 millions de paramètres suffit pour faire du tool calling fiable sur smartphone, montre ou objet connecté. Pour une PME, cela signifie trois bénéfices directs en 2026 : coût marginal nul, latence quasi-nulle, données qui restent locales. Le périmètre fonctionnel reste circonscrit au tool calling, mais c'est précisément ce périmètre qui couvre la majorité des cas d'usage produit côté client. À surveiller dans les six prochains mois : les premiers éditeurs SaaS qui l'embarqueront dans leurs offres, et l'apparition probable de variantes encore plus spécialisées par secteur métier.
Charles-Henry Soulet accompagne les PME et indépendants sur leur stratégie SEO et GEO via Treelink. Il a déployé une trentaine de sites Webflow et conseille les dirigeants sur l'intégration de l'IA dans leurs canaux d'acquisition. Plus d'informations sur la page À propos.
Publié le 31 mai 2026, mis à jour le 31 mai 2026.
Sources : Dépôt GitHub officiel Cactus Compute Needle, Annonce technique sur le blog Cactus, Discussion Hacker News (667 points, mai 2026).



.jpg)